

实战Python教程网络爬虫pdf百度网盘下载地址?
本书从原理到实践,循序渐进地讲述了使用Python教程开发网络爬虫的核心技术。全书从逻辑上可分为基础篇、实战篇和爬虫框架篇三部分。基础篇主要介绍了编写网络爬虫所需的基础知识,包括网站分析、数据抓取、数据清洗和数据入库。网站分析讲述如何使用Chrome和Fiddler抓包工具对网站做全面分析;数据抓取介绍了Python教程爬虫模块Urllib和Requests的基础知识;数据清洗主要介绍字符串操作、正则和BeautifulSoup的使用;数据入库讲述了MySQL和MongoDB的操作,通过ORM框架SQLAlchemy实现数据持久化,进行企业级开发。实战篇深入讲解了分布式爬虫、爬虫软件的开发、12306抢票程序和微博爬取等。框架篇主要讲述流行的爬虫框架Scrapy,并以Scrapy与Selenium、Splash、Redis结合的项目案例,让读者深层次了解Scrapy的使用。此外,本书还介绍了爬虫的上线部署、如何自己动手开发一款爬虫框架、反爬虫技术的解决方案等内容。
本书使用Python教程 3.X编写,技术先进,项目丰富,适合欲从事爬虫工程师和数据分析师岗位的初学者、大学生和研究生使用,也很适合有一些网络爬虫编写经验,但希望更加全面、深入理解Python教程爬虫的开发人员使用。
Python教程作者简介:
黄永祥,CSDN博客专家和签约讲师,多年软件研发经验,主要从事机器人流程系统研发、大数据系统研发、网络爬虫研发以及自动化运维系统研发。擅长使用Python教程编写高质量代码,对Python教程有深入研究,热爱分享和新技术的探索。
Python教程目录:
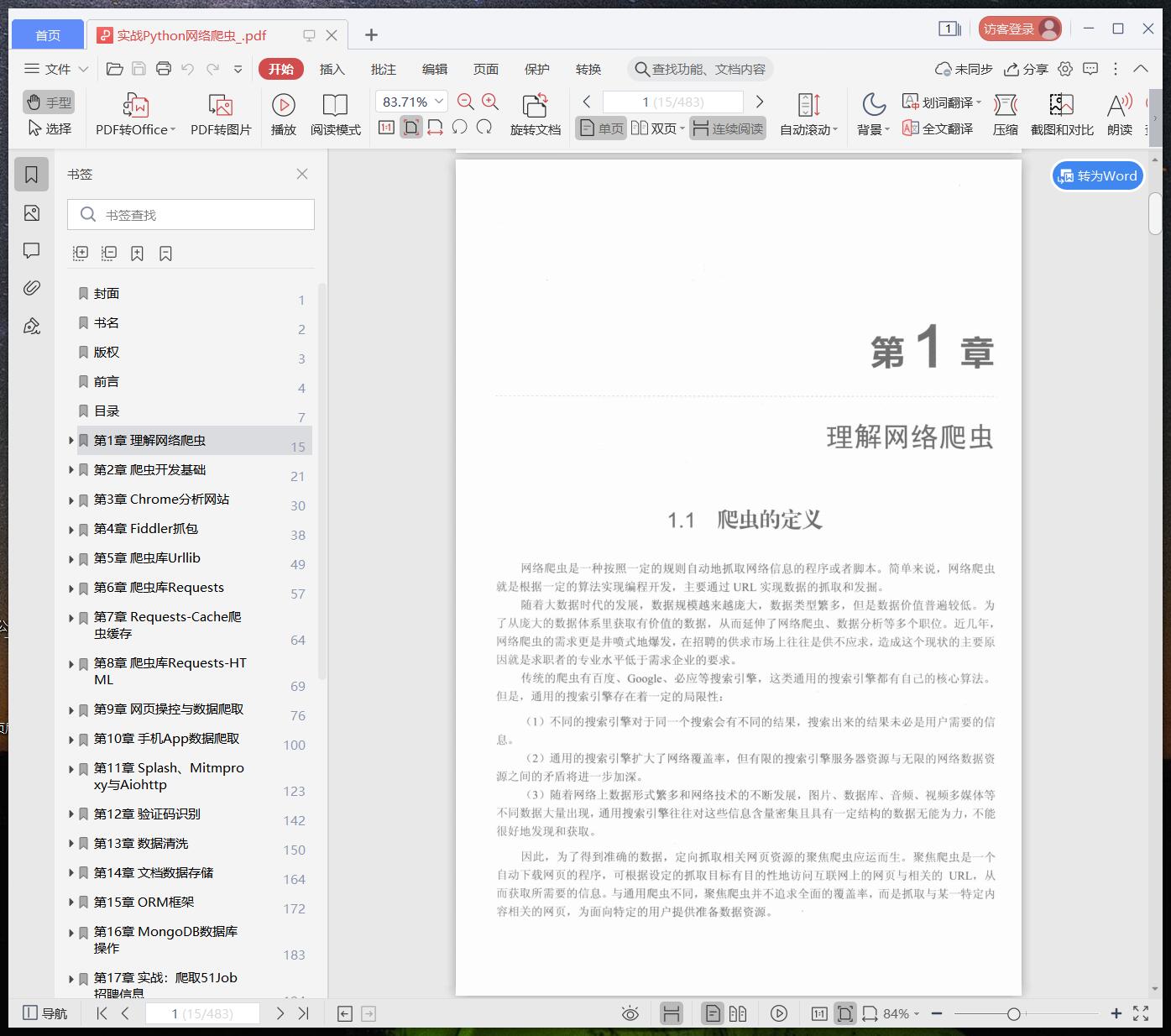
第1章 理解网络爬虫 1
第2章 爬虫开发基础 7
第3章 Chrome分析网站 16
第4章 Fiddler抓包 24
第5章 爬虫库Urllib 35
第6章 爬虫库Requests 43
第7章 Requests-Cache爬虫缓存 50
第8章 爬虫库Requests-ML 55
第9章 网页操控与数据爬取 62
第10章 手机App数据爬取 86
第11章 Splash、Mitmproxy与Aiohttp 109
第12章 验证码识别 128
第13章 数据清洗 136
第14章 文档数据存储 150
第15章 ORM框架 158
第16章 MongoDB数据库操作 169
第17章 实战:爬取51Job招聘信息 180
第18章 实战:分布式爬虫——QQ音乐 193
第19章 实战:12306抢票爬虫 211
第20章 实战:玩转微博 244
第21章 实战:微博爬虫软件开发 278
第22章 Scrapy爬虫开发 317
第23章 Scrapy扩展开发 341
第24章 实战:爬取链家楼盘信息 386
第25章 实战:QQ音乐全站爬取 402
第26章 爬虫的上线部署 415
第27章 反爬虫的解决方案 435
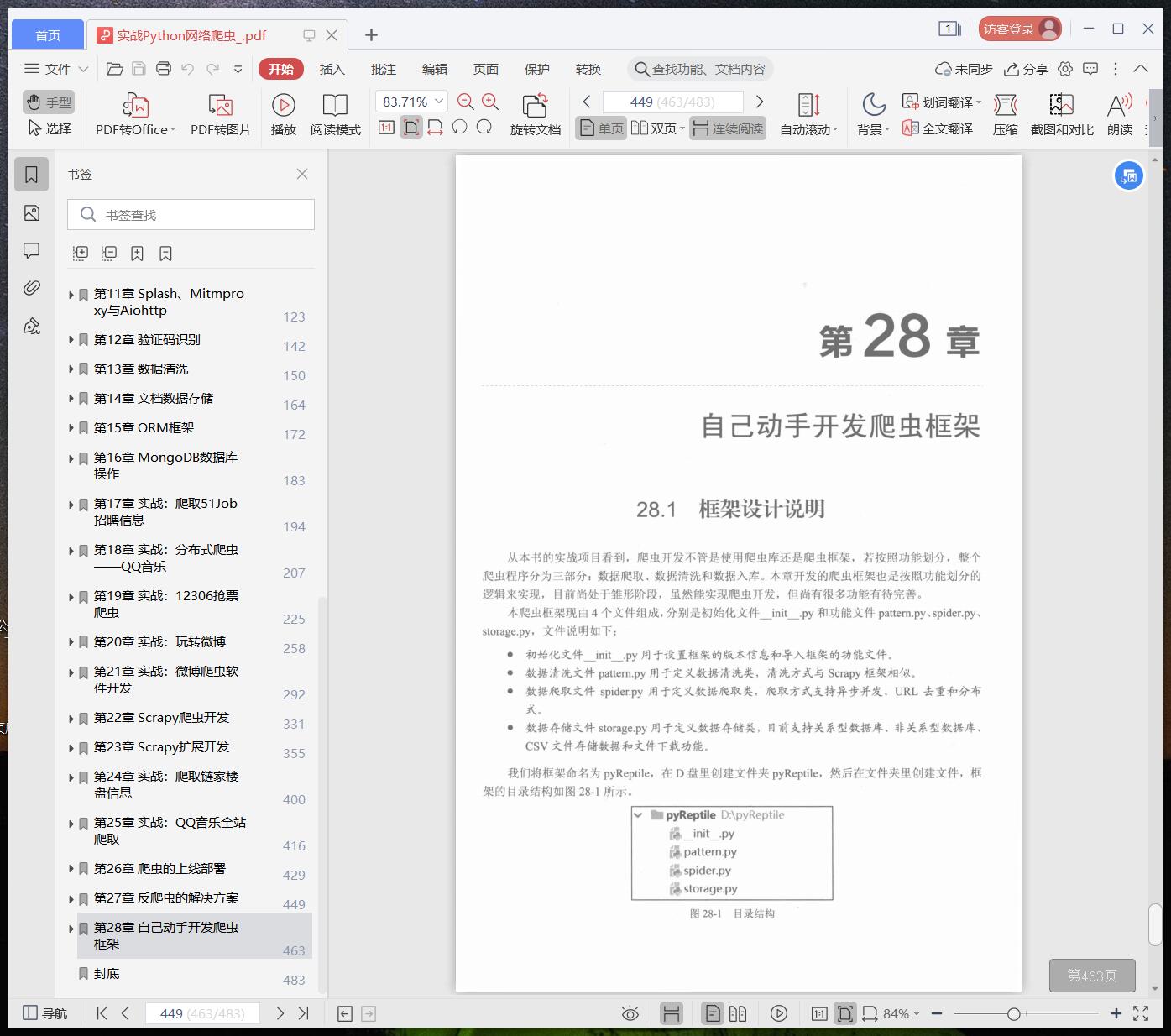
第28章 自己动手开发爬虫框架 449
点击下载
本文来自投稿,不代表亲测学习网立场,如若转载,请注明出处:https://www.qince.net/%e5%ae%9e%e6%88%98python%e6%95%99%e7%a8%8b%e7%bd%91%e7%bb%9c%e7%88%ac%e8%99%abpdf%e7%94%b5%e5%ad%90%e4%b9%a6%e7%b1%8d%e4%b8%8b%e8%bd%bd%e7%99%be%e5%ba%a6%e7%bd%91%e7%9b%98.html
郑重声明:
本站所有内容均由互联网收集整理、网友上传,并且以计算机技术研究交流为目的,仅供大家参考、学习,不存在任何商业目的与商业用途。 若您需要商业运营或用于其他商业活动,请您购买正版授权并合法使用。
我们不承担任何技术及版权问题,且不对任何资源负法律责任。
如遇到资源无法下载,请点击这里失效报错。失效报错提交后记得查看你的留言信息,24小时之内反馈信息。
如有侵犯您的版权,请给我们私信,我们会尽快处理,并诚恳的向你道歉!
